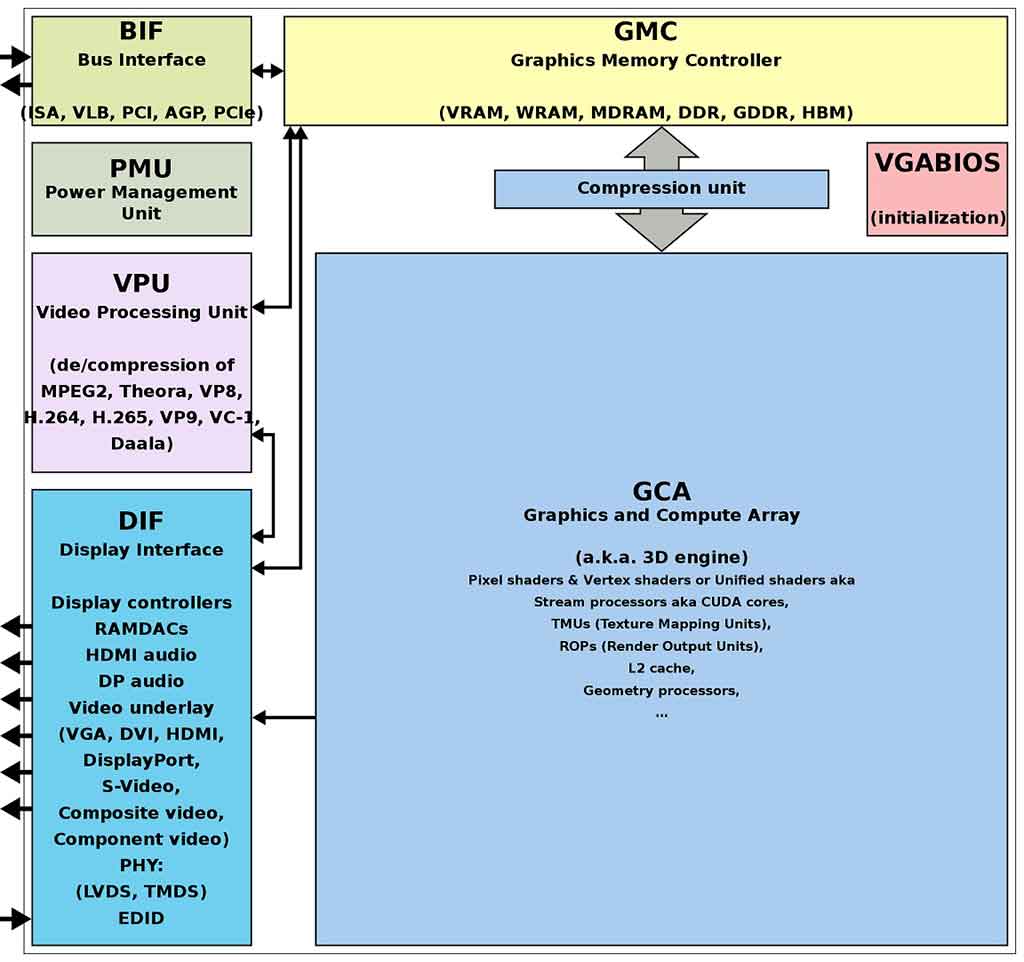
GPU là gì ?
Bộ xử lý đồ họa (Graphics Processing Unit – GPU) là một mạch điện tử chuyên dụng được thiết kế để tăng tốc việc xử lý hình ảnh dành cho thiết bị hiển thị. GPU được sử dụng trong các hệ thống nhúng, điện thoại di động, máy tính cá nhân, máy trạm và máy chơi game. GPU hiện đại mang lại hiệu suất cao trong việc xử lý đồ họa máy tính và xử lý hình ảnh. Cấu trúc thiết kế của chúng hiệu quả hơn so với các đơn vị xử lý trung tâm (CPU) trong các thuật toán xử lý các khối dữ liệu lớn song song. Trong máy tính cá nhân, GPU có thể xuất hiện trên card VGA (cạc video hay cạc đồ họa) hoặc được nhúng trên bo mạch chủ. Trong một số CPU nhất định, chúng được nhúng vào lõi CPU.
Thuật ngữ “GPU” được đặt ra bởi Sony trong PlayStation console vào năm 1994. Thuật ngữ này được phổ biến bởi Nvidia trong năm 1999, công ty đưa ra thị trường các card GeForce 256 là “GPU đầu tiên trên thế giới”. Rival ATI Technologies đưa ra thuật ngữ ” visual processing unit ” hoặc VPU với việc phát hành Radeon 9700 vào năm 2002.
Xem thêm: TOP Cạc đồ họa tốt nhất năm 2021: GPU đỉnh cho dàn PC gaming của bạn
Lịch sử phát triển GPU
Những năm 1970
Các hệ thống arcade đã sử dụng chip đồ họa chuyên dụng từ những năm 1970. Trong phần cứng trò chơi video đầu tiên. Bộ chuyển đổi video MB14241 của Fujitsu đã được sử dụng để tăng tốc độ vẽ đồ họa sprite cho các trò chơi arcade.
Trong các thiết bị gia đình, Atari 2600 vào năm 1977 đã sử dụng bộ chuyển đổi video có tên là “Bộ điều hợp giao diện truyền hình”. Máy tính 8 bit Atari (1979) có ANTIC , bộ xử lý video diễn giải các hướng dẫn mô tả một “danh sách hiển thị” các chế độ bitmap hoặc ký tự cụ thể và nơi lưu trữ bộ nhớ
Những năm 1980
NEC μPD7220 là sản phẩm tiên phong thực hiện xử lý đồ họa máy tính trên chip tích hợp, tạo điều kiện cho việc thiết kế card đồ họa video hiệu suất cao với chi phí thấp. Nó trở thành GPU nổi tiếng nhất cho đến giữa những năm 1980.
Năm 1984, Hitachi đã phát hành ARTC HD63484, bộ xử lý đồ họa CMOS đầu tiên cho PC. ARTC có khả năng hiển thị độ phân giải lên tới 4K khi ở chế độ đơn sắc và nó được sử dụng trong một số card đồ họa PC và thiết bị đầu cuối vào cuối những năm 1984
Năm 1987, hệ thống đồ họa IBM 8514 được phát hành là một trong những card đầu tiên cho các máy tính của IBM PC có chức năng xử lý 2D trong phần cứng điện tử .
IBM ‘s độc quyền chuẩn hiển thị (VGA) được giới thiệu vào năm 1987, với độ phân giải tối đa 640 x 480 pixel. Vào tháng 11 năm 1988, NEC Home Electronics đã tuyên bố thành lập Hiệp hội Tiêu chuẩn Điện tử Video (VESA) để phát triển và quảng bá một tiêu chuẩn hiển thị Super VGA (SVGA) như một sự kế thừa cho tiêu chuẩn hiển thị VGA độc quyền của IBM. SVGA cho phép hiển thị đồ họa độ phân giải lên tới 800 × 600 pixel, tăng 36%.
Những năm 1990

Vào năm 1991, S3 Graphics đã giới thiệu S3 86C911, được các nhà thiết kế đặt tên theo chiếc Porsche 911 như một dấu hiệu cho thấy sự gia tăng hiệu suất của nó. 86C911 tạo ra một làn sóng mới vào năm 1995, tất cả các nhà sản xuất chip đồ họa PC lớn đã thêm tính năng tăng tốc 2D cho chip của họ.
Trong suốt những năm 1990, khả năng tăng tốc GUI 2D tiếp tục phát triển. Khi khả năng sản xuất được cải thiện, mức độ tích hợp của chip đồ họa cũng tăng theo.
Vào giữa thập niên 90, đồ họa 3D thời gian thực ngày càng trở nên phổ biến trong các game arcade, máy tính và console, dẫn đến nhu cầu ngày càng tăng đối với phần cứng tăng tốc đồ họa 3D. Fujitsu Pinolite, bộ xử lý hình học 3D đầu tiên cho máy tính cá nhân được phát hành vào năm 1997. Cũng trong năm này Mitsubishi đã phát hành 3D pro/2MP, một GPU có đầy đủ tính năng cho các máy trạm và máy tính để bàn Windows NT; ATi sử dụng nó cho card đồ họa FireGL 4000 của họ, được phát hành vào năm 1997.
OpenGL xuất hiện vào đầu những năm 90 dưới dạng API đồ họa chuyên nghiệp, nhưng ban đầu bị các vấn đề về hiệu năng khiến nó không phổ biến bằng API Glide đang thống trị trên PC vào cuối những năm 90. Tuy nhiên, những vấn đề này đã nhanh chóng được khắc phục và API Glide đã bị đánh bại.
Việc triển khai OpenGL được phổ biến trong thời gian này, ảnh hưởng của OpenGL cuối cùng đã thúc đẩy các phần cứng hỗ trợ nó rộng rãi. Vào cuối những năm 90, Microsoft giới thiệu DirectX như một đối trọng với OpenGL. Cách tiếp cận ban đầu làm cho DirectX trở nên ít phổ biến hơn, điều này khiến DirectX thường bị chậm một thế hệ. (Xem thêm: OpenGL là gì để hiểu rõ hơn)
2000 đến 2010
Nvidia là hãng đầu tiên sản xuất một con chip có khả năng đổ bóng, trên GeForce 3 (tên mã NV20). Được sử dụng trong các máy Xbox, nó đã cạnh tranh với PlayStation 2 (sử dụng DSP vectơ tùy chỉnh được tăng tốc bằng phần cứng; thường được gọi là VU0 / VU1).
Với sự ra mắt của dòng GeForce 8, được sản xuất bởi Nvidia, GPU trở thành một thiết bị điện toán đa dụng hơn. Ngày nay, các GPU song song đã bắt đầu xâm nhập vào lĩnh vực tính toán của CPU trong các ứng dụng nghiên cứu chuyên biệt, được đặt tên là GPU Computing hoặc GPGPU (General Purpose Computing on GPU) cho mục đích tính toán trên GPU. GPGPU tại thời điểm đó được gọi là shader tính toán (ví dụ CUDA, OpenCL, DirectCompute).
Nền tảng CUDA của Nvidia, được giới thiệu lần đầu tiên vào năm 2007, là mô hình lập trình được áp dụng phổ biến sớm nhất cho điện toán GPU. Gần đây OpenCL đã được hỗ trợ rộng rãi. OpenCL là một tiêu chuẩn mở được xác định bởi Tập đoàn Khronos, cho phép phát triển mã cho cả GPU và CPU, chú trọng vào tính di động. Các giải pháp OpenCL được Intel, AMD, Nvidia và ARM hỗ trợ và theo báo cáo gần đây của Evan’s Data, OpenCL là nền tảng phát triển GPGPU được sử dụng rộng rãi nhất bởi các nhà phát triển ở cả Mỹ và Châu Á Thái Bình Dương.
2010 đến nay
Năm 2010, Nvidia bắt đầu hợp tác với Audi để cung cấp sức mạnh tính toán cho ô tô. Các GPU Tegra cung cấp chức năng tăng cường cho các hệ thống điều hướng và giải trí của ô tô. Những tiến bộ trong công nghệ GPU trên ô tô đã giúp thúc đẩy công nghệ tự lái. Card Radeon HD 6000 của AMD được phát hành vào năm 2010 và năm 2011, AMD đã phát hành GPU 6000M Series của họ để sử dụng trong các thiết bị di động. Kiến trúc Kepler của Nvidia ra đời năm 2012 và được sử dụng trong các dòng card 600 và 700 của Nvidia. Một tính năng mới trong kiến trúc GPU này bao gồm công nghệ điều chỉnh tốc độ xung nhịp của lõi GPU để tăng hoặc giảm tùy theo mức yêu cầu của hệ thống. Kiến trúc Kepler được sản xuất trên quy trình 28 nm.
PS4 và Xbox One đã được phát hành vào năm 2013, cả hai đều sử dụng GPU dựa trên AMD Radeon HD 7850 và 7790. Các nhà sản xuất kính thực tế ảo VR đã khuyến nghị GTX 970 và R9 290X hoặc tốt hơn tại thời điểm phát hành. Pascal là thế hệ card đồ họa phổ thông tiếp theo do Nvidia phát hành năm 2016. Dòng GeForce 10 nằm trong thế hệ card đồ họa này. Nvidia đã phát hành một card đồ họa không dành cho người dùng phổ thông theo kiến trúc Volta mới, Titan V. Bao gồm sự gia tăng số lượng lõi CUDA, thêm lõi Tensor và HBM2. Các lõi Tensor là các lõi được thiết kế đặc biệt để học sâu, trong khi bộ nhớ có xung nhịp thấp hơn, nhưng cung cấp một bus bộ nhớ cực rộng, hữu ích cho mục đích của Titan V. Để nhấn mạnh rằng Titan V không phải là một card đồ họa chơi game, Nvidia đã loại bỏ hậu tố “GeForce GTX” để phân biệt với card đồ họa chơi game phổ thông.
Vào ngày 20 tháng 8 năm 2018, Nvidia đã ra mắt GPU sê-ri RTX 20 bổ sung các lõi mới cho GPU, cải thiện hiệu suất của chúng về hiệu ứng ánh sáng. GPU Polaris 11 và Polaris 10 của AMD được chế tạo theo quy trình 14 nanomet. Thiết kế của họ dẫn đến sự gia tăng đáng kể hiệu suất trên mỗi watt tiêu thụ của card đồ họa AMD. AMD cũng đã phát hành loạt GPU Vega cho thị trường cao cấp với tư cách là đối thủ cạnh tranh với dòng Titan V cao cấp của Nvidia, nó cũng được trang bị lõi HBM2.
Các công ty thiết kế và sản xuất GPU
Nhiều công ty đã sản xuất GPU dưới một số hương hiệu. Trong năm 2009, Intel, Nvidia và AMD/ATI là những người dẫn đầu thị phần, với 49,4%, 27,8% và 20,6% thị phần tương ứng. Tuy nhiên, những con số đó bao gồm các giải pháp đồ họa tích hợp của Intel. Nếu không tính số lượng card đồ họa tích hợp, Nvidia và AMD kiểm soát gần 100% thị trường đồ họa máy tính đến năm 2018. Thị phần tương ứng của họ là 66% và 33%. Điện thoại thông minh hiện nay cũng sử dụng chủ yếu GPU Adreno của Qualcomm, GPU PowerVR từ Imagination Technologies và GPU Mali từ ARM .
GPU trong lĩnh vực trí tuệ nhân tạo AI
Với sự xuất hiện của học sâu, tầm quan trọng của GPU đã tăng lên. Trong nghiên cứu được thực hiện bởi Indigo, người ta thấy rằng khi đào tạo các mạng thần kinh học sâu, GPU có thể nhanh hơn 250 lần so với CPU. Sự phát triển bùng nổ của Deep Learning trong những năm gần đây được thúc đẩy bởi sự xuất hiện của GPU computing. Đã có một số cạnh tranh trong lĩnh vực này, nổi bật nhất là Tensor Processing Unit (TPU) do Google sản xuất. Tuy nhiên, nó yêu cầu thay đổi mã hiện tại và GPU vẫn đang rất phổ biến.
Phân loại GPU theo mục đích sử dụng
Trong máy tính cá nhân, có hai dạng GPU chính:
- Card đồ họa chuyên dụng – còn gọi là đồ họa rời hay card rời (cạc rời) .
- Đồ họa tích hợp – còn được gọi là: giải pháp đồ họa dùng chung, bộ xử lý đồ họa tích hợp (IGP) hoặc kiến trúc bộ nhớ hợp nhất (UMA).
Thiết kế GPU cho mục đích cụ thể
Hầu hết các GPU được thiết kế để sử dụng cho một mục đích cụ thể, đồ họa 3D thời gian thực hoặc các tính toán hàng loạt khác:
Chơi game
- GeForce GTX, RTX
- Nvidia Titan X
- AMD Radeon HD
- Các dòng AMD Radeon R5, R7, R9, RX, Vega và Navi
Cloud gaming (chơi game trên nền tảng đám mây)
- Nvidia Grid
- AMD Radeon Sky
Máy trạm
- Nvidia Quadro
- Nvidia Titan X
- AMD FirePro
- AMD Radeon Pro
- AMD Radeon VII
Máy trạm cloud
- Nvidia Tesla
- AMD FireStream
Artificial Intelligence Cloud (trí tuệ nhân tạo trên nền tảng đám mây)
- Nvidia Tesla
- AMD Radeon Instinct
Xe tự động / không người lái
- Nvidia Drive PX
GPU chuyên dụng là gì
Các GPU mạnh nhất thường giao tiếp với bo mạch chủ bằng khe cắm mở rộng như PCI Express (PCIe) hoặc Cổng đồ họa tăng tốc (AGP) và thường có thể được thay thế hoặc nâng cấp một cách dễ dàng, nếu bo mạch chủ có khả năng hỗ trợ việc nâng cấp. Một vài card đồ họa vẫn sử dụng các khe cắm Kết nối ngoại vi (PCI), nhưng băng thông của chúng bị giới hạn đến mức chúng thường chỉ được sử dụng khi không có khe cắm PCIe hoặc AGP.

GPU chuyên dụng không nhất thiết phải có thể tháo rời và cũng không nhất thiết phải giao tiếp với bo mạch chủ bằng các khe cắm tiêu chuẩn. Thuật ngữ “chuyên dụng” dùng để chỉ các card đồ họa chuyên dụng có các lõi xử lý đồ họa và RAM dành riêng cho chúng, chứ không phải các GPU chuyên dụng đều có thể tháo rời. Hơn nữa, RAM thường được xử dụng là loại dành riêng cho các GPU (GDDR). Đôi khi, các hệ thống có GPU riêng, được gọi là hệ thống “DIS”, trái ngược với các hệ thống “UMA. GPU chuyên dụng cho máy laptop thường được giao tiếp thông qua một khe không tiêu chuẩn và thường là độc quyền do hạn chế về kích thước và trọng lượng. Các cổng như vậy vẫn có thể được coi là PCIe hoặc AGP, ngay cả khi chúng không thể thay thế về mặt vật lý.
Các công nghệ như SLI của Nvidia và CrossFire của AMD cho phép nhiều GPU xử lý đồng thời cho một màn hình, tăng sức mạnh xử lý cho đồ họa.
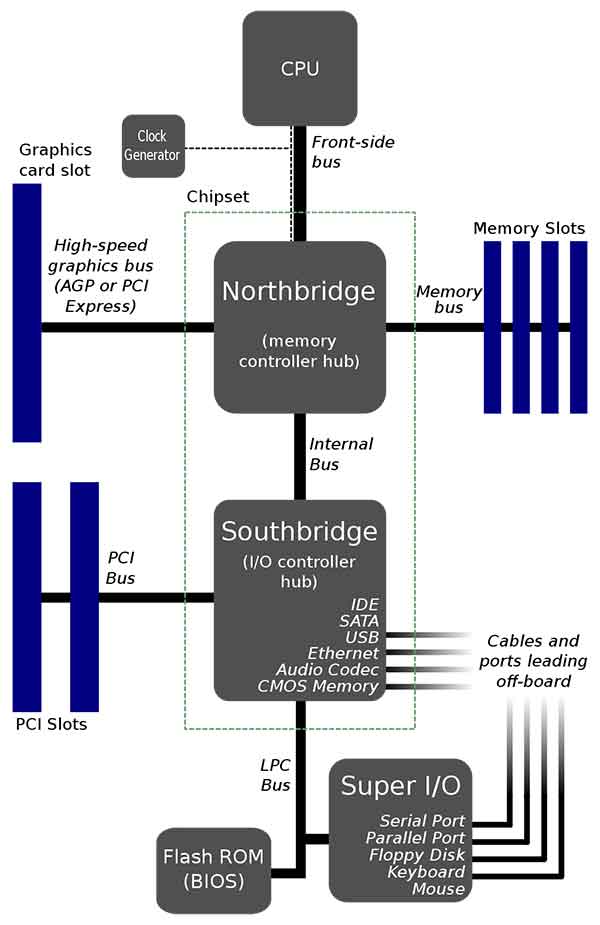
Bộ xử lý đồ họa tích hợp là gì
Đơn vị xử lý đồ họa tích hợp (IGPU), Đồ họa tích hợp, giải pháp đồ họa dùng chung, bộ xử lý đồ họa tích hợp (IGP) hoặc kiến trúc bộ nhớ hợp nhất (UMA) sử dụng một phần RAM của hệ thống thay vì bộ nhớ đồ họa chuyên dụng. Các IGP có thể được tích hợp vào bo mạch chủ như một phần của chipset hoặc trên một CPU (như AMD APU hoặc Intel HD Graphics ).
Trên một số bo mạch chủ nhất định, IGP của AMD có thể sử dụng bộ nhớ chuyên dụng dành riêng cho nó. Đây là một khối bộ nhớ hiệu suất cao cố định dành riêng cho GPU sử dụng. Đầu năm 2007, các máy tính có đồ họa tích hợp chiếm khoảng 90% trong tất cả các lô hàng PC. Chúng ít tốn kém hơn so với xử lý đồ họa chuyên dụng, nhưng có hiệu năng thấp hơn.
Trong lịch sử, đồ họa tích hợp được coi là không phù hợp để chơi game 3D hoặc chạy các chương trình đồ họa chuyên sâu nhưng có thể chạy các chương trình ít chuyên sâu hơn như Adobe Flash. Ví dụ các IGP được cung cấp từ SiS và VIA vào khoảng năm 2004. Tuy nhiên, các bộ xử lý đồ họa tích hợp hiện đại như AMD Accelerated Processing Unit và Đồ họa HD của Intel có khả năng xử lý đồ họa 2D hoặc đồ họa 3D nhẹ.
Do các tính toán GPU cực kỳ tốn bộ nhớ, nên đồ họa tích hợp có thể ngốn tài nguyên của hệ thống như RAM khiến chúng tương đối chậm. Các IGP (đồ họa tích hợp) có thể chiếm băng thông bộ nhớ lên tới 30 GB/giây từ RAM hệ thống, trong khi đó, một card đồ họa chuyên dụng có thể cung cấp băng thông lên tới 264 GB/giây giữa RAM GDDR chuyên dụng và lõi GPU. Băng thông bus bộ nhớ thấp có thể hạn chế hiệu suất của các GPU tích hợp, mặc dù bộ nhớ đa kênh có thể giảm thiểu sự thiếu hụt này.
Lớp GPU mới hơn này cạnh tranh với đồ họa tích hợp trong thị trường máy tính để bàn và máy tính xách tay cấp thấp. Các giải pháp phổ biến nhất là HyperMemory của ATI và TurboCache của Nvidia .
Card đồ họa lai có phần đắt hơn đồ họa tích hợp, nhưng rẻ hơn nhiều so với card đồ họa chuyên dụng. Giải pháp này vẫn chia sẻ bộ nhớ với RAM hệ thống và trang bị một số lượng nhỏ bộ nhớ chuyên dụng GDDR để cache, có tác dụng bù đắp độ trễ cao của RAM hệ thống. Các công nghệ trong PCI Express có thể thực hiện điều này. Mặc dù các giải pháp này đôi khi được quảng cáo có tổng số lượng bộ nhớ lớn, nhưng không đề cập chính xác là có bao nhiêu phần bộ nhớ chuyên dụng (hay còn gọi là Ram on card).
Tính toán bằng GPU – GPGPU là gì
Việc sử dụng một đơn vị xử lý đồ họa cho mục đích tính toán (GPGPU) ngày càng trở nên phổ biến như là một hình thức thay thế CPU trong một số lĩnh vực, điển hình như trong công nghệ blockchain hay đào Bitcoin, phần lớn người dùng xử dụng các GPU để xử lý tính toán chuỗi khối.
Khái niệm này biến sức mạnh tính toán khổng lồ của lõi gia tốc đồ họa hiện đại thành sức mạnh tính toán cho mục đích chung, trái ngược với việc chỉ dùng để xử lý đồ họa. Trong một số ứng dụng yêu cầu hoạt động véc tơ lớn, điều này có thể mang lại hiệu suất cao hơn nhiều lần so với CPU thông thường.
Hai nhà thiết kế GPU riêng biệt, AMD và Nvidia, đang bắt đầu theo đuổi phương pháp này với một loạt các ứng dụng. Cả Nvidia và AMD đã hợp tác với Đại học Stanford để tạo ra một ứng dụng dựa trên GPU cho dự án điện toán phân tán Folding @ home, để tính toán số liệu vector. Trong một số trường hợp nhất định, GPU tính toán nhanh hơn bốn mươi lần so với CPU thường được sử dụng bởi các ứng dụng đó.
GPGPU có thể được sử dụng cho nhiều loại nhiệm vụ song song. Chúng thường phù hợp với các tính toán thông lượng cao thể hiện tính song song dữ liệu để khai thác kiến trúc SIMD của GPU.
Hơn nữa, các máy tính hiệu năng cao dựa trên GPU đang bắt đầu đóng một vai trò quan trọng trong quy mô lớn. Ba trong số 10 siêu máy tính mạnh nhất thế giới tận dụng khả năng tính toán song song của GPU.
GPU hỗ trợ các phần mở rộng API cho ngôn ngữ lập trình C như OpenCL và OpenMP. Hơn nữa, mỗi nhà cung cấp GPU đã giới thiệu API riêng chỉ hoạt động với card của họ, AMD APP SDK của AMD và CUDA của Nvidia. Những công nghệ này cho phép các chương trình C có thể tận dụng khả năng của GPU để hoạt động song song trên các bộ đệm lớn, trong khi vẫn sử dụng CPU khi cần. CUDA cũng là API đầu tiên cho phép các ứng dụng dựa trên CPU truy cập trực tiếp vào tài nguyên của GPU để tính toán cho mục đích chung mà không bị giới hạn khi sử dụng API đồ họa.
Từ năm 2005, người ta đã quan tâm đến việc sử dụng hiệu suất được cung cấp bởi GPU cho tính toán nói chung và để tăng tốc độ trong lập trình di truyền nói riêng. Thông thường, lợi thế về hiệu suất chỉ thể hiện khi chạy các chương trình hoạt động song song trên nhiều mẫu, sử dụng kiến trúc SIMD của GPU. Tuy nhiên, cũng có thể đạt được lợi thế tăng tốc đáng kể bằng cách chuyển chúng hoàn toàn sang GPU, và xử lý ở đó. Một GPU hiện đại có thể dễ dàng đồng thời xử lý hàng trăm ngàn chương trình rất nhỏ.
Một số GPU máy trạm hiện đại, chẳng hạn như Nvidia Quadro sử dụng kiến trúc Volta và Turing, có lõi xử lý cho các ứng dụng học sâu. Trong các GPU hiện đại của Nvidia, các lõi này được gọi là Tensor Cores. Những GPU này thường có hiệu suất FLOPS tăng đáng kể, sử dụng phép nhân và chia ma trận 4×4, dẫn đến hiệu suất phần cứng lên tới 128 TFLOPS trong một số ứng dụng. Những lõi Tensor Cores này cũng được cho là xuất hiện trong các card phổ thông chạy kiến trúc Turing, và trong dòng card Navi của AMD.
GPU ngoài (eGPU) là gì
GPU bên ngoài là bộ xử lý đồ họa nằm hoàn toàn bên của máy tính. Bộ xử lý đồ họa bên ngoài thường được sử dụng với máy tính laptop. Máy tính laptop có thể có một lượng RAM đáng kể và bộ xử lý trung tâm (CPU) đủ mạnh, nhưng thường thiếu bộ xử lý đồ họa mạnh mẽ, và thay vào đó có chip đồ họa tích hợp tiết kiệm năng lượng hơn. Các chip đồ họa tích hợp thường không đủ mạnh để chơi các game mới nhất hoặc cho các tác vụ đồ họa chuyên sâu, chẳng hạn như chỉnh sửa video.
Do đó, xuất hiện nhu cầu bổ sung GPU vào một số bus ngoài của máy tính xách tay. PCI Express là giao tiếp thường được sử dụng cho mục đích này. Ví dụ, có thể là cổng ExpressCard hoặc mPCIe (PCIe × 1, tối đa 5 Gbit/s) hoặc cổng Thunderbolt 1, 2 hoặc 3 (PCIe × 4, tối đa 10, 20 hoặc 40 Gbit/s tương ứng). Những cổng đó thường có sẵn trên một số hệ thống máy tính laptop.
Một cột mốc đáng chú ý là quyết định của Apple hỗ trợ GPU ngoài với mac OS High Sierra 10.13.4. Ngoài ra còn có một số nhà cung cấp phần cứng lớn (HP, Alienware, Razer) sản xuất các dock mở rộng Thunderbolt 3 eGPU. Sự hỗ trợ này đã thúc đẩy việc triển khai eGPU cho những người dùng có nhu cầu hiệu năng đồ họa.
Nguồn: biên tập bởi thietbiketnoi.com
Xem thêm:
- Gateway là gì ? thuật ngữ chuyên ngành viễn thông – công nghệ thông tin
- DLC trong chơi game là gì và nó hoạt động như thế nào?
- PPPoE là gì ? – Tài liệu công nghệ kỹ thuật số
Tìm kiếm bởi Google:
- gpu acceleration là gì
- card gpu là gì
- gpu có nghĩa là gì
- share gpu memory là gì
- opengl rendering gpu là gì







